When I write an R markdown file in RStudio and Knit HTML, my formulas (inline using $..$ or display using $$..$$) can be displayed properly. However, when I push my .md file to GitHub, these formulas cannot be displayed. They only show $..$ and $$..$$. Is there a way to let GitHub know how to parse latex formulas? Thanks!
Is there a way to let GitHub know how to parse latex formulas?
Some sites provide users with a service that would fit your need without any javascript involved: on-the-fly generation of images from url encoded latex formulas.
codecogs.com
iTex2Img.
given the following markdown syntax
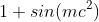
it will display the following image
Note: In order for the image to be properly displayed, you'll have to ensure the querystring part of the url is percent encoded. You can easily find online tools to help you with that task, such as www.url-encode-decode.com
I also looked for how to render math on GitHub pages, and after a long time of research I found a nice solution.
I used KateX to render formulas server side: it is really faster than MathJaX.
Please note that same solution could be arranged to work also client side, but, I prefer server side rendering, cause
you know your server environment, but you don't know the client environment of your visitors
it is also faster client side, if the formulas are rendered on the server, only once.
I wrote an article showing the steps, I hope it can help math divulgation: see Math on GitHub Pages.
Related
I would like to setup a homepage and publish several R code mixed with text, pictures and references. Obviously that's what a lot of people do:
https://feliperego.github.io/blog/2015/10/23/Interpreting-Model-Output-In-R
https://yihui.org/knitr/demo/wordpress/
http://3.14a.ch/archives/2015/03/08/how-to-publish-with-r-markdown-in-wordpress/
RWordPress does not seem to support graphical outputs from the script. Instead of discussing the multitude of errors I received and options I tried, my simple question is: How did the above listed examples manage to put R code and graphs on their websites? (I haven't tried to contact those homepage owners, but this will be the next step, if no explanation can be found.)
You have several options. It depends if you want to build your website from scratch or not. In the first case, I recommend you to have a look at:
bookdown: very nice for documentation. You can find many examples on the web, for instance the bookdown documentation
blogdown: more general than bookdown. This gives very nice websites (mine is built using blogdown for instance). blogdown is based on hugo: you can find many themes.
In both cases, you write standard Rmarkdown and build your site by executing the markdowns. You can build the site locally for preview or deploy them on the web (manually or by a continuous integration system as gitlab pages). The point of using these packages is reducing the burden of handling formatting and links between pages.
The short answer is a mixture of manual and automatic generation. If you look at my website (www.jamescurran.co.nz), you'll find articles like the ones you want to write.
I achieve this in a variety of ways. Sometimes I get knitr to produce the HTML, and then I hack it into shape on the website. Other times, I use a mixture of short-tags like
[code language = "R"]
data(cars)
[/code]
and/or HTML like
<pre><code>
data(cars)
</code><pre>
The images I upload and then use Wordpress' editor to insert the correct links. It's not very satisfactory, but unless you have a hosting platform that allows you to have static content, then most of the automated solutions that go straight from R Markdown won't work.
I'm producing plenty of analyses in R and utilizing the .html Markdown format to present and communicate work. Often, my manager will need to correct/add to the text which accompanies the code blocks, and has practically no interaction with the code blocks. The analyses are typically produced by myself alone, so code collaboration is a low priority.
In an ideal world, he could open up the .html and edit the text in a browser, which I understand is not possible.
Are there any simple solutions for this? I am sure this is a common problem so there must be an easy solution I am overlooking. Here are the current solutions being considered:
Use Git (but my manager wouldn't like to learn Git)
Use Jupyter Notebooks (but I would prefer to stick with R Markdown for integration with RStudio and for the reproducible templates)
Knit the Markdown as a word document with manual version control on a shared network, allow tracking of changes in the word document, and copy-and-paste over changes made to the .Rmd file
The latter is least elegant but most likely to be used at the moment. If you have any suggestions, please let me know!
Here's a solution that is tailor-made your exact situation.
Use jupytext for bi-directional lossless interoperability between jupyter notebooks and R Markdown documents!
Maybe redoc is an option for you. Haven't tried it myself and it's still experimental but it would allow you to collaborate via Word. Basically the Word document can be edited and passed back to RMarkdown with all changes. See here.
I suggest you try trackdown https://claudiozandonella.github.io/trackdown/
trackdown offers a simple answer to collaborative writing and editing of R Markdown (or Sweave) documents. Using trackdown, the local .Rmd (or .Rnw) file is uploaded as plain-text in Google Drive where, thanks to the easily readable Markdown (or LaTeX) syntax and the well-known online interface offered by Google Docs, collaborators can easily contribute to the writing and editing of the narrative part of the document. After integrating all authors’ contributions, the final document can be downloaded and rendered locally.
Moreover, you can hide code chunks setting hide_code = TRUE (they will be automatically restored when downloaded). This prevents collaborators from inadvertently making changes to the code that might corrupt the file and it allows collaborators to focus only on the narrative text ignoring code jargon.
You can also upload the actual Output (i.e., the resulting complied document) in Google Drive together with the .Rmd (or .Rnw) document. This helps collaborators to evaluate the overall layout, figures and tables and it allows them to use comments on the pdf to propose and discuss suggestions.
I am getting started with the reproducible research tools in R, and I'm pretty excited about the prospects. Sweave/Knitr/Markdown, all that stuff is great. I use RStudio, and they have done a great job of integrating those tool, and I hear that StatET does a nice job putting all that together as well.
I don't write academic papers in LaTeX, and all the people I work with use Word, so I am very interested in an effective workflow to use ODFWeave to make documents.
My usual process is:
Develop the code chunks in my IDE (RStudio, in my case)
Go back and insert these into a ODT document and fill in the surrounding text.
run ODFweave
My problem is that I get confused in tracking code chunks and putting them into the ODF document. Keeping the ODF document in sync as I create the code is annoying, so I'd rather wait and insert the code chunks by name.
So finally, here are my questions:
What are people's suggestions for tracking code chunks or on how to optimize this workflow?
Can anyone recommend tools or tips for keeping track of the code chunks you write?
Being a software geek and a data nerd, I naturally imagine a piece of software doing this for me. Like I'd have a database of code chunks, and when writing the ODF document I'd be able to click on a chunk to insert it into my ODF file.
Has one anyone created this sort of thing?
When you check the number of items tagged odfweave on SO, you will notice that it is rarely used compared to Sweave and knit-offs. I do not fully understand why it did not take off, possible because of table-generation being such a nuisance (at least that what I remember from my attempts).
Since many customers insist on Word-Documents, we are using two alternatives currently:
Create html, e.g. with RStudio/knitr/rmd, and read it with Word. This is not really a good workflow, to get reasonable document you need much manual post-processing, but it works more or less.
You can also use the path via RDCOM. I don't remember what's the state of art here, because we have totally given up using it since the conditions of licensing were not transparent to us.
Use pandoc. This approach produces documents that do not need manual post-processing in MS-Word, but the range of features to create a nice layout (cross-linked images, figure numbering) are limited; it might be a problem that we are not yet good enough in using pandoc in its full.
I'm building an application to view pdf's through a browser without the need of a plugin on mobile devices. I tried ImageMagick and ghostscript to covert the pages to images but they are far too large and text becomes unclear. I see website offering a service of converting pdf's into html and do a descent job but I can't find an example of how this is accomplished. Any help is much appreciated. Thanks!
EDIT: I seem to have read the question backwards. In this case it might be best to parse through the PDF and then format some HTML based on what you find. I believe the javapdf option is capable of this, but I haven't used any of these so I am not sure. If worse comes to worst and you can't find software to disassemble a PDF, you might be able to write your own disassembler in Java or PHP by reading the PDF specification. Best of luck!
http://www.adobe.com/devnet/pdf/pdf_reference.html - PDF Specification (Adobe Modified Version, because they are most popular you may want to support their extensions)
-- OLD -- These websites probably write their own proprietary software to do the trick. If you are truly interested in this undertaking, I would suggest parsing the HTML to get the data and style information and using it to format some sort of PDF writer APIs. A quick Google search yields the following: -- END OLD --
http://www.cutepdf.com/Solutions/
http://ruby-pdf.rubyforge.org/pdf-writer/doc/index.html
http://asprise.com/product/javapdf/
If you are looking at converting PDF to HTML and planning to run the conversion on a server, then you can try pdf2html. It is a program packaged as part of poppler-utils. I do not know how the program accomplishes it.
I was googling and came across the below link explaining how scridb.com implements conversion.
http://coding.scribd.com/2010/06/01/the-perils-of-stacking/
I'm currently looking at different solutions getting 2 dimensional mathematical formulas into webpages. I think that the wikipedia solution (generating png images from LaTeX sourcecode) is good enough until we get support for MathML in webbrowsers.
I suddenly realized that it might be possible to create a Google Charts API equivalent for mathformulas. Has this already been done? Is it even possible due to the strange characters involved in LaTeX-code?
I would like to hit an url like latex2png.org/api/?eq="E = mc^2" and get the following response:
edit:
Thanks for the answers sofar. However, I am already aware of several tools to generate png images from latex source code (both online and from my commandline), but what I was looking for was a simple way to get the image via an Http GET request. Perhaps such a service does not exist.
Update
As #hughes (and others) pointed out, the previous Google Chart API has been deprecated.
The example I wrote still works as of Sept 2015, but a new one shall be used now (documentation):
Old answer
Google Chart can do it (Documentation):
http://chart.apis.google.com/chart?cht=tx&chl=%5CLaTeX
I'm using this with Google Docs, because it doesn't support math yet.
chart.apis.google with background color changed
https://chart.apis.google.com/chart?cht=tx&chf=bg,s,FFFF00&chl=%0D%0A4x_0%5CDelta%28x%29%2B3%5CDelta%28x%29%2B2%5CDelta%28x%5E2%29%3E0%0D%0A
or chart.apis.google with background color transparent and resized
For better readability URL needs to be decoded.
https://chart.apis.google.com/chart?cht=tx&chs=428x35&chf=bg,s,FFFFFF00&chl=
4x_0\Delta(x)+3\Delta(x)+2\Delta(x^2)>0
Data structure looks like this
{
"cht":"tx",
"chs":"428x35",
"chf":"bg,s,FFFFFF00",
"chl":"n4x_0\Delta(x) 3\Delta(x) 2\Delta(x^2)>0"
}
https://chart.apis.google.com/chart?cht=tx&chs=428x35&chf=bg,s,FFFFFF00&chl=%0D%0A4x_0%5CDelta%28x%29%2B3%5CDelta%28x%29%2B2%5CDelta%28x%5E2%29%3E0%0D%0A
You could try the Online image generator for mathematical formulas for a start.
mathurl is a mathematical version of TinyURL.com. It allows you to reference LaTeXed mathematical expressions using a short url. For example, http://mathurl.com/?5v4pjw will show [LaTeX output Image] which you can then edit. More details on mathurl’s help page
I just ran across MathJax on Ajaxian [via Wayback Machine]:
MathJax seems to have a chance at being a practical solution that offers a high quality display of LaTeX and MathML math notation in HTML pages.
The output is remarkably beautiful, and it's all pure HTML and CSS, which makes it scalable and selectable. Performance is currently a bit sluggish, but this is recognized.
As everyone has said, there are many services that do this already. Here is another easy one that I've used a number of times (and you can install it locally on your server if necessary):
http://www.codecogs.com/components/equationeditor/equationeditor.php
I'd take a good look at how the MediaWiki LaTeX support does it and borrow from there.
Please check out this site for a way to create TeX documents without any software installed. You can then snippet the result image with any screen capture method and embed the resulting image into a any website.
Go to http://sharelatex.com
The software is free to use, but you need to register to create documents.